|
Data Storage And Handling
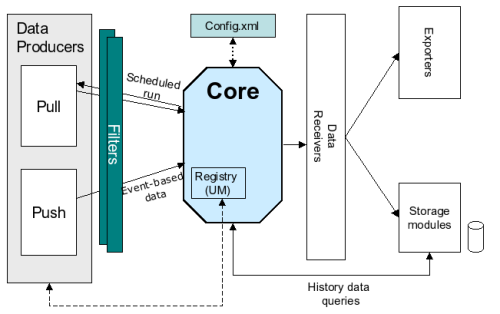
Each MonALISA service can create a local database for short or long term history for the monitored information.
The monitoring is done by a multi threaded engine for
parallel and independent data collection tasks
execution. Failing monitoring modules are
automatically removed from execution queue so they
don't affect the rest of the system.
Clients can send two types of requests (predicates) to
the services: history requests, that are served from the
local database, and subscriptions for new data events.
A special type of client, used by repositories or other services, can be used
to store in a central place, selected monitoring information from
many sites. It can be used to store long term history with high resolution.
Both the services and the repositories share the same
flexible mechanism to use database systems. From the configuration
files the administrator can choose the time interval for
which the data is stored and the data representation
that is best for the site. The repositories currently use a
dual time resolution system, storing data at both 1
minute and 100 minutes resolutions for the entire time
interval (usually one year long). This structure allows
the storage engine to automatically select the best data
source in terms of resolution and database
interrogation speed. For example a repository will
choose to use the 1 minute resolution structures for a
hourly chart but will switch to a 100 minutes
resolution when the user requests a monthly report.
Database storage is doubled by an adaptive memory
buffer that tries to keep as much history data in
memory as possible, looking at the JVM to determine
the free memory and total memory sizes and changing
its boundaries accordingly.
MonALISA has the ability to transport and store different types of monitoring data.
This data must be user-definable so that any service
user can implement its own data type. It also has to
be self-describing so that the database engine can
store it in transparent manner. The engine will
transport and store only Java objects that extend the
base MLData object. Any subclass of MLData must
implement some simple functions that define the
fields that are stored in the database and their
format. The field format is specified in an abstract
form and is translated into the proper SQL query
depending on the database backend in use.
Currently we support MySQL, PostgreSQL,
Microsoft SQL Server and the embedded Mckoi
database system.
Figure 1: Data Storage And Handling
Measurement units
The data producing modules can attach extra information to the parameters they produce by using the Registry object to map parameters to Unit instances.
A Unit object defines:
- type (scalar, bit, byte, percent, text, image ...);
- time base (second, millisecond, hour etc);
- unit multiplier (K, M, G ...);
- incremental flag (the new value is a difference over the previous value);
- transient flag (this data is mostly redundant and should not be stored);
- transient history flag (store the changes of the transient data values - for
example record the time of a software version change);
- other attributes that help the client to automatically display the data in an
intelligent
|